Robots.txt जेनरेटर
किसी भी वेबसाइट के लिए एक Robots.txt फ़ाइल बनाने के लिए हमारे मुफ्त रोबोट्स.txt जनरेटर टूल का उपयोग करें और महत्वहीन पेजों को प्रतिबंधित करके, क्रॉलर अनुरोधों को कम करके और उन्हें महत्वपूर्ण पेजों के लिए सहेज कर क्रॉलिंग को प्रभावी ढंग से प्रबंधित करें।
के बारे में Robots.txt जेनरेटर
Robots.txt जेनरेटर के बारे में
Robots.txt जनरेटर एक आर्टिफिशियल इंटेलिजेंस टूल है जो एक टेक्स्ट फाइल बनाता है। फ़ाइल खोज इंजन के लिए निर्देश रखती है। दूसरे शब्दों में, फ़ाइल सर्च इंजन की क्रॉलिंग क्रिया को नियंत्रित करती है।
Robots.txt फ़ाइल में खोज इंजन क्रॉलर से छिपी हुई सामग्री का विवरण होता है। फ़ाइल में दिए गए निर्देशों के आधार पर, खोज इंजन पृष्ठों के माध्यम से क्रॉल करे या न करे। आइए सरल शब्दों का प्रयोग करें। वेबसाइट सामग्री की समीक्षा करने के लिए खोज इंजन क्रॉलर का उपयोग करते हैं। यदि आप अपनी वेबसाइट के किसी विशिष्ट भाग को छुपाना चाहते हैं, तो उसे Robots.txt फ़ाइल में डालें।
फ़ाइल बनाते समय, Robots.txt जनरेटर आपको खोज इंजन चुनने की अनुमति देता है। उदाहरण के लिए, मान लें कि आप अपनी सामग्री को केवल Yahoo और MSN से छिपाना चाहते हैं; और आप ऐसा करने के लिए Google को सक्षम करना चाहते हैं। उस स्थिति में, आप टूल की सेटिंग बदल सकते हैं। उदाहरण के लिए, Google पर "अनुमति दें" चुनें; और अन्य खोज इंजनों में "अस्वीकार करें"।
Robots.txt जेनरेटर क्या है?
रोबोट्स.टेक्स्ट जेनरेटर को रोबोट्स एक्सक्लूज़न प्रोटोकॉल भी कहा जाता है। पाठ फ़ाइल उपयोगकर्ता को वेबसाइट की सामग्री को वर्गीकृत करने में मदद करती है, सबसे पहले; उपयोगकर्ता अच्छी और बुरी सामग्री को छाँटता है। फिर वे पाठ फ़ाइल में खोज इंजन क्रॉलर से सामग्री को छिपाने या दिखाने के निर्देश दर्ज करते हैं।
robots.txt जेनरेटर का उपयोग कैसे करें?
उपकरण का उपयोग करना आसान है। हालाँकि, यदि आप नए हैं, तो कृपया इसके उपयोग के बारे में जानने के लिए इन चरणों का पालन करें:
- विकल्प डिफ़ॉल्ट-सभी रोबोट सभी खोज इंजनों को आपकी वेबसाइट के माध्यम से क्रॉल करने की अनुमति देता है। आप सभी खोज इंजनों को अस्वीकार करने के लिए भी इस विकल्प का उपयोग कर सकते हैं।
- क्रॉल-विलंब विकल्प खोज इंजनों की क्रॉलिंग क्रिया को धीमा कर देता है। Google इस विकल्प का समर्थन नहीं करता है। तो यह इसे अनदेखा कर देगा। हालांकि, अन्य सर्च इंजन जैसे बिंग और याहू 10 की क्रॉल देरी का उपयोग करते हैं। ये सर्च इंजन 24 घंटे (एक दिन) को दस सेकंड की विंडो में विभाजित करेंगे। लगभग 8,640 खिड़कियां। वे एक विंडो में एक पेज क्रॉल करेंगे।
- अगला साइटमैप आता है। यदि आपके पास अपनी वेबसाइट के लिए साइटमैप नहीं है तो इस विकल्प को खाली छोड़ दें।
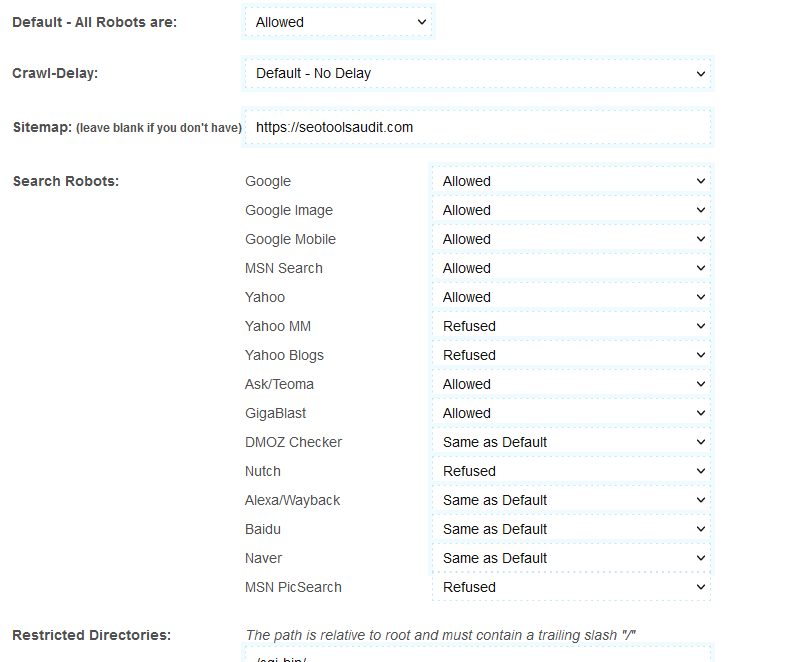
- अंत में, आपको Google, Yahoo, MSN, आदि जैसे विकल्प दिखाई देंगे। अब, उन सर्च इंजनों को चुनें जिन्हें आप अनुमति देना चाहते हैं और जिन्हें आप छिपाना चाहते हैं।
- उपरोक्त विवरण भरने के बाद, "Create Robots.txt" पर क्लिक करें। टूल आपके लिए टेक्स्ट फ़ाइल बनाएगा। फ़ाइल को अपने वेबपेज के नीचे रखें।

Robots.txt जेनरेटर के लाभ
यदि आप पाठ फ़ाइल को मैन्युअल रूप से लिखते हैं, तो इसमें बहुत समय लगता है। लेकिन आप फाइल को कुछ ही सेकंड में Robots.txt जनरेटर टूल से बना सकते हैं। आपको बस उपयुक्त विकल्पों का चयन करना है और "Create Robots.txt" बटन पर क्लिक करना है।
सॉफ्टवेयर फ़ाइल को सहेजने का अवसर भी प्रदान करता है। इसलिए, आप कई फाइलें बना और सहेज सकते हैं।
Robots.txt जेनरेटर की विशेषताएं
उपकरण आपको क्रॉलिंग को नियंत्रित करने की अनुमति देता है। इसमें क्रॉल डिले फीचर भी है। यदि एक से अधिक क्रॉलर एक साथ एक वेबपेज में प्रवेश करते हैं, तो पेज की प्रतिक्रिया दोनों के बीच विभाजित हो जाती है। इसलिए, पूरी प्रक्रिया समय लेने वाली हो जाती है। क्रॉल विलंब ऐसे मुद्दों से बचने में मदद करता है। यह लगातार दो क्रॉलरों के बीच समय की देरी पैदा करता है। टूल में सर्च इंजन चुनने का विकल्प है। यदि आप खोज इंजनों को अनुमति देते हैं या अस्वीकार करते हैं तो इससे मदद मिलेगी।
आप robots.txt जेनरेटर के साथ SEO रैंकिंग कैसे सुधार सकते हैं?
फ़ाइल को रखना वैकल्पिक है। लेकिन यदि आप ऐसा करते हैं, तो robots.txt फ़ाइल आपकी वेबसाइट के समग्र प्रदर्शन और SEO रैंकिंग को बढ़ा देती है। इसका कारण यह है कि क्रॉलर रोबोट्स.टेक्स्ट के साथ बहुत जल्दी जानकारी खोज लेते हैं। फ़ाइल के साथ, उन्हें नई सामग्री खोजने की आवश्यकता नहीं है। इसके बजाय, पाठ फ़ाइल उन सभी को देती है। इसलिए, क्रॉलर द्वारा आपकी वेबसाइट पर बिताया जाने वाला कुल समय काफ़ी कम है। इसलिए सर्च इंजन क्रॉलर्स का मानना है कि इस वेबसाइट का यूजर एक्सपीरियंस अच्छा है। लोगों को सूचना जल्दी मिल जाती है।
निचली पंक्ति, क्रॉलर आपकी वेबसाइट के बारे में अच्छी रिपोर्ट लेते हैं, जो कि Robots.txt फ़ाइल के साथ होती है। इस प्रकार, आपकी वेबसाइट की SEO रैंकिंग में सुधार होता है।
पूछे जाने वाले प्रश्न
क्या robots.txt जनरेटर क्रॉल को नियंत्रित करता है?
किसी वेबसाइट पर नए और अपडेटेड पेजों को खोजना क्रॉल करना कहलाता है। और robots.txt जनरेटर क्रॉलिंग को नियंत्रित कर सकता है। जब आप Txt फ़ाइल बनाते हैं, तो आप उन खोज इंजनों का चयन करते हैं जिन्हें क्रॉल करने की अनुमति होगी और क्रॉल करने की अनुमति नहीं होगी।
क्या Robots.txt जनरेटर अनुक्रमण को नियंत्रित करता है?
नहीं। यह केवल रेंगने को नियंत्रित करता है। अनुक्रमण क्रॉलिंग से अलग है। यह एक वेबसाइट पर सामग्री को व्यवस्थित करने की प्रक्रिया है। अनुक्रमण की विधि पृष्ठों के बीच संबंध बनाती है और लिंक का विश्लेषण करती है।
क्या robots.txt जनरेटर साइटमैप जैसा ही है?
नहीं। साइटमैप में वेबसाइट के बारे में जानकारी होती है। खोज इंजन द्वारा आयोजित समग्र सामग्री के बारे में एक विचार प्राप्त करने के लिए खोज इंजन साइटमैप का उपयोग करते हैं। यह खोज इंजनों को क्रॉल की आवश्यकता वाले पृष्ठों के बारे में सूचित करता है। दूसरी ओर, robots.txt फ़ाइल क्रॉलर के लिए है। पाठ फ़ाइल क्रॉलर को बताती है कि किस पर क्रॉल करना है और क्या नहीं।
Robots.txt फ़ाइल में निर्देश क्या हैं?
robots.txt फ़ाइल में तीन अलग-अलग निर्देशों का उपयोग किया जाता है। वे क्रॉल-विलंब, अनुमति देने और अस्वीकार करने वाले हैं।
- क्रॉल विलंब खोज इंजनों को ओवरलोडिंग से रोकता है। कहते हैं कि एक खोज इंजन एक वेबपेज पर कई क्रॉलर भेज रहा है। पेज भीड़भाड़ वाला और अनुत्तरदायी हो जाता है। क्रॉल-विलंब ऐसे मुद्दों से बचा जाता है। सर्च इंजन क्रॉलर में देरी करके, robots.txt फ़ाइल ट्रैफ़िक को सुव्यवस्थित करती है।
- निर्देश "अनुमति देना" URL को अनुक्रमणित करने में सक्षम बनाता है। अधिक से अधिक URL जोड़ने के लिए सुविधा का उपयोग करें। यह ई-कॉमर्स साइटों के लिए बहुत मददगार है। खरीदारी वेबसाइटों की लंबी सूची है।
- "अस्वीकार करना" निर्देश क्रॉलर को शामिल लिंक पर जाने से रोकता है।
क्या मैं मुख्य पृष्ठ पर "अनुमति नहीं दे रहा" निर्देश जोड़ सकता हूँ?
आप कर सकते हैं। लेकिन अगर आप ऐसा नहीं करते हैं तो इससे मदद मिलेगी। सर्च इंजन एक निश्चित क्रॉल बजट पर काम करते हैं। वे प्रत्येक वेबसाइट के लिए एक विशेष क्रॉल बजट निर्धारित करते हैं। होम पेज वेबसाइट के दिल की तरह है।
जब आप मुख्य पृष्ठ को अस्वीकार करते हैं, तो क्रॉलर यह मानकर चलते हैं कि आपकी साइट अनुक्रमित होने के लिए तैयार नहीं है। और होमपेज को ब्लॉक करने से क्रॉल डेप्थ में वृद्धि हो सकती है क्योंकि होमपेज मुख्य पेज होता है जो आमतौर पर पूरी वेबसाइट से लिंक होता है।
तो, यह क्रॉलर द्वारा अपडेट के लिए पृष्ठों और पोस्ट की संख्या तक पहुंच में कमी का कारण बनेगा। इसलिए, यह सलाह दी जाती है कि मुख्य पृष्ठ पर "अस्वीकार करें" निर्देश का उपयोग न करें।
LATEST BLOGS
खोज
-
लोकप्रिय एसईओ उपकरण
- साहित्यिक चोरी चेकर
- व्याख्या उपकरण
- कीवर्ड स्थिति परीक्षक
- व्याकरण जाँचकर्ता
- डोमेन अथॉरिटी चेकर
- पेजस्पीड इनसाइट्स चेकर
- Image Compression Tool
- रिवर्स इमेज सर्च
- Page Authority checker
- Text To Speech
- बैकलिंक चेकर
- बैकलिंक निर्माता
- Domain Age Checker
- Website Ping Tool
- वेबसाइट समीक्षक
- कीवर्ड घनत्व परीक्षक
- पेज साइज चेकर
- शब्द काउंटर
- मोज़रैंक चेकर