Robots.txt Generator
Use our free Robots.txt generator tool to create a Robots.txt file for any website and effectively manage crawling by restricting unimportant pages, reducing crawler requests and saving them for important pages.
About Robots.txt Generator
The Robots.txt generator is an Artificial Intelligence Tool that generates a text file. The file holds the instructions for search engines. In other words, the file controls the crawling action of the search engines.
The Robots.txt file contains the content details hidden from the search engine crawlers. Based on the instructions in the file, the search engines shall or shall not crawl through pages. Let us use simple words. Search engines use crawlers to review the website content. If you want to hide a specific part of your website, put it in the Robots.txt file.
While creating the file, the Robots.txt generator allows you to choose the search engine. For instance, say you want to hide your content only from Yahoo and MSN; and you want to enable Google to do so. In that case, you may change the settings of the tool. For example, select "Allow" on Google; and "Reject" in other search engines.
What is Robots.txt Generator?
The Robots.txt generator is also called Robots Exclusion Protocol. The text file helps the user to categorize the content of a website, First; the user sorts good and bad content. Then they enter the instructions to hide or show the content from the search engine crawlers in the text file.
How to use the Robots.txt Generator?
The tool is easy to use. However, if you are new, please follow these steps to learn about its usage:
- The option Default-All Robots allows all the search engines to crawl through your website. You may also use this option to reject all search engines.
- The crawl-delay option slows down the crawling action of the search engines. Google doesn't support this option. So it will just ignore it. However, other search engines like Bing and Yahoo use a crawl delay of 10. These search engines will divide 24 hours (one day) into ten-second windows. Approximately 8,640 windows. They will crawl one page in one window.
- Next comes the sitemap. Leave this option blank if you do not have a sitemap for your website.
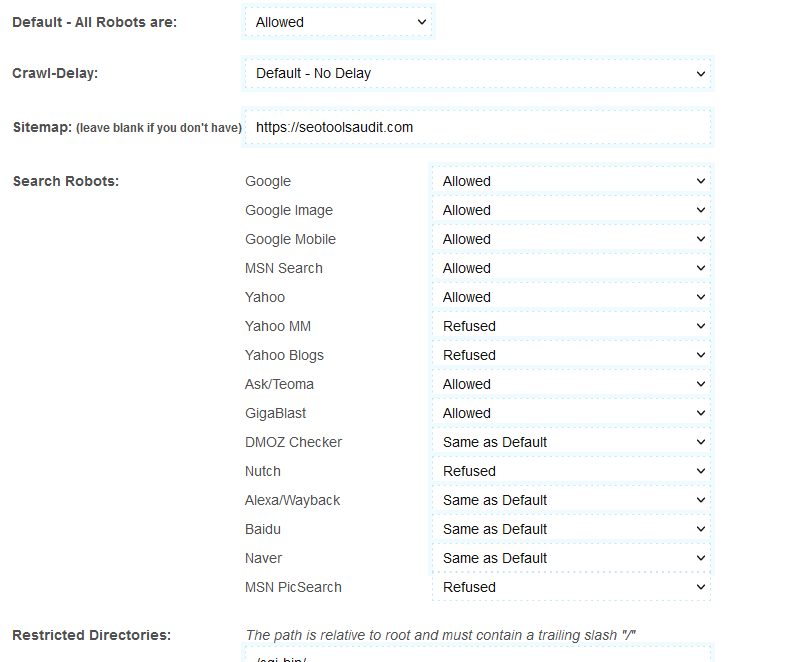
- At last, you will see options like Google, Yahoo, MSN, etc. Now, choose those search engines you want to allow and those you want to hide from.
- After filling in the above details, click "Create Robots.txt." The tool will create the text file for you. Place the file at the foot of your webpage.

Benefits of Robots.txt Generator
If you write the text file manually, it consumes lots of time. But you can create the file with the Robots.txt generator tool within seconds. All you need to do is select the suitable options and click the "Create Robots.txt" button.
The software also provides the opportunity of saving the file as well. Therefore, you can create and save multiple files.
Features of Robots.txt Generator
The tool allows you to control crawling. It has crawl delay features as well. If more than one crawler enters a webpage simultaneously, the page's response splits between the two. Therefore, the entire process becomes time-consuming. The crawl delay helps to avoid such issues. It creates a time delay between two consecutive crawlers. The tool has the option to choose the search engines. It would help if you allowed or disallowed search engines.
How can you improve the SEO ranking with the Robots.txt generator?
It is optional to place the file. But if you do so, the robots.txt file enhances your website's overall performance and SEO ranking. This is because the crawlers find the information very quickly with Robots.txt. With the file, they need not search for new content. Instead, the text file gives them all. So, the overall time the crawler spends on your website is significantly less. Therefore, search engine crawlers believe this website's user experience is good. People get the information quickly.
The bottom line, the crawlers take a good report about your website with the Robots.txt file. Thus, the SEO ranking of your website improves.
FAQs
Does the Robots.txt generator control the crawl?
Searching new and updated pages on a website is called crawling. And the Robots.txt generator can control crawling. While you create the Txt file, you select the search engines that shall be allowed to crawl and not allowed to crawl.
Does the Robots.txt generator control indexing?
No. It only controls crawling. Indexing is different from crawling. It is the process of organizing the content on a website. The method of indexing creates connections between the pages and analyzes the links.
Is the Robots.txt generator the same as the sitemap?
No. Sitemap contains information about the website. Search engines use the sitemap to get an idea about the overall content held by the search engine. It notifies the search engines about the pages requiring the crawl. On the other hand, the robots.txt file is for crawlers. The text file tells the crawlers what to crawl on and what not to.
What are the directives in the Robots.txt file?
There are three different directives used in the robots.txt file. They are crawl-delay, allowing, and disallowing.
- The crawl delay prevents the search engines from overloading. Say a search engine is sending multiple crawlers to a webpage. The page becomes crowded and unresponsive. Crawl-delay avoids such issues. By delaying the search engine crawlers, the robots.txt file streamlines the traffic.
- The directive "Allowing" enables indexing a URL. Use the feature to add as many URLs as possible. It is of immense help to e-commerce sites. The Shopping websites have lengthy lists.
- The "Disallowing" directive stops the crawlers from visiting the links included.
Can I add a "Disallowing" directive on the main page?
You may. But it would help if you didn't do it. Search engines work on a fixed crawl budget. They set a particular crawl budget for every website. The home page is like the heart of the website.
When you disallow the main page, the crawlers go under the assumption that your site is not ready to be indexed. and blocking the homepage could cause an increase in the crawl depth as the homepage is the main page which usually links to the entire website.
So, this will cause a decrease in the access to the number of pages and posts by the crawler for updates. Therefore, it is advisable not to use the "Disallow" directive on the main page.
LATEST BLOGS
Search
-
Popular Seo Tools
- Plagiarism Checker
- Paraphrasing Tool
- Keyword Position Checker
- Grammar Checker
- Domain Authority Checker
- PageSpeed Insights Checker
- Image Compression Tool
- Reverse Image Search
- Page Authority checker
- Text To Speech
- Backlink Checker
- Backlink Maker
- Domain Age Checker
- Website Ping Tool
- Website Reviewer
- Keyword Density Checker
- Page Size Checker
- Word Counter
- Mozrank Checker